1 Introduction
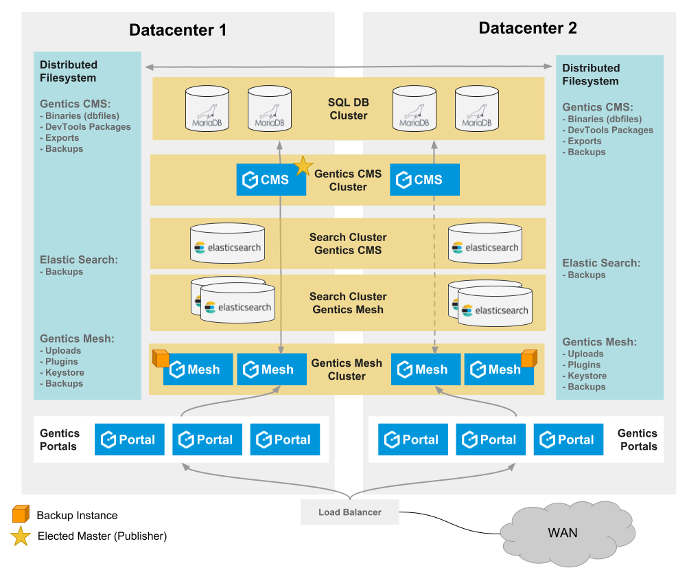
The following infrastucture graphic should give you a basic overview of the components that are used in a typical Gentics Content Management Platform Cluster where Gentics CMS is just one part of.

1.1 Components
1.1.1 MariaDB Cluster
A MariaDB Galera Cluster can be to setup to be used for Activiti, Keycloak and Gentics CMS.
1.1.2 Gentics CMS
The Gentics CMS server takes the central role in the infrastucture overview. Most of the used components are connected with this service. See the description of its functionality for more information.
1.1.3 Gentics Mesh
Starting with version 2.0.0 clustering with OrientDB is no longer part of the professional support by Gentics. For high availability setups, it is recommended to use Gentics Mesh SQL.
1.1.4 Gentics Portal
The Portal framework instances are stateless and be deployed multiple times without any special configuration changes.
Custom extensions which add state to the Portal will need a tailored setup in a clustered deployments.
1.1.5 Elasticsearch
There are three dedicated roles within an Elasticsearch cluster.
- Master Node: Accepts write requests
- Data Node: Distributes and provides shards
- Ingest Node: Uses the ingest plugins to process added documents
A single instance can own multiple roles.
Individual search clusters for Gentics CMS and Gentics Mesh can be used if a DMZ or dedicated security policy mandates this.
1.1.6 Keycloak
All Gentics Products support keycloak as a IAM provider.
The Keycloak service can also be deployed in a clustered fashion. The central MariaDB cluster should be used to store the service data in this case. More details on the setup and configuration can be found in the Keycloak Clustering Documentation.
1.1.7 Language Tool
The Language Tool is the basis for the Aloha Editor Spellcheck Plugin.
The Language Tool Server is stateless and does not require any database. We provide a docker image for this service.
1.2 Filesystem
A common filesystem needs to be used in all clustering scenarios. The uploads into Gentics Mesh and Gentics CMS need to be synchronized across this filesystem.
Using individual filesystems will cause issues since the uploaded files can be updated. A manual synchronization would cause inevitable issues with data consistency.
Possible solutions to this requirement are:
- Use of a distributed filesystem (e.g. GlusterFS, Ceph)
- Use of a S3 backed object store and fuse based mount on all cluster instances.
- A master/slave aproach to NFS. Some NFS solutions can replicate the data in background across multiple locations. Only a single NFS would in turn be mounted in both locations. If one of the storage systems fails or the connection between the datacenters is disrupted a failover process can kick in which switches the used NFS to the still accessible location.
1.3 Load Balancing
Most of the service clusters (e.g. Elasticsearch cluster, Gentics Mesh cluster) require a load balancing mechanism in-front in order to correctly handle failover, redundancy.
Solutions like Kubernetes already provide a build-in mechanism to distribute requests across multiple instances.
1.4 Multiple Datacenters
The previous listed components can also be used across multiple datacenters. This solution may be desired when redundancy should be increased.
The filesystem for uploads needs to be distributed in this case.
2 Overview on Gentics CMS cluster support
2.1 Architecture
The architecture of a CMS instance is built from the following components:
| Component | Requirements for cluster support |
|---|---|
| SQL Database (MySQL or MariaDB) | Full read/write access to the shared/clustered database from all CMS cluster nodes. See Backend database |
| Local Filesystem | Read/write access to some shared filesystem paths. See Filesystem mounts |
| Gentics CMS | Cluster support provided by Hazelcast IMDG |
2.2 Functionality
All user interaction (through the UI or REST API) can be made against any of the CMS cluster nodes. It is therefore possible to distribute incoming client requests to all CMS cluster nodes by using a load balancer (session stickyness is not required).
Automatic (background) jobs are executed on only one of the CMS cluster nodes (the master node). These include:
- Scheduler Tasks
- Publish Process
- Dirting of objects
- Devtools package synchronization
The master node is automatically elected by the cluster, whenever this is necessary. This means that if the current master node leaves the cluster, another node will be elected as new master node. There will always be exactly one master node, except in special cases while performing an update (see Updating for details).
3 Setup
3.1 Backend database
All cluster nodes must have read/write access to the same backend database system (MySQL or MariaDB). The backend database itself can also be setup as a cluster of database nodes (so that – for example – each CMS cluster node accesses a separate database cluster node of the same database cluster), but this is optional.
3.2 Filesystem mounts
All cluster nodes must have read/write access to the following list of shared filesystem paths (e.g. mounted via NFS):
| Path | Description |
|---|---|
/cms/data |
Contains binary contents of images/file, resized images for GenticsImageStore, Publish Log files, Devtool Packages and statically published files |
Optionally, also the CMS configuration located at /cms/conf/ can be shared between the cluster nodes to ensure that all nodes have identical configuration.
4 Configuration
4.1 Activate Feature
feature: cluster: true
4.2 Hazelcast Configuration
By default, the hazelcast configuration file must be placed at /cms/conf/hazelcast.xml.
The only configuration setting, which is mandatory for the CMS cluster, is setting an individual instance name for each cluster node. This is necessary for the automatic changelog system (used for updating) to work.
<?xml version="1.0" encoding="UTF-8"?> <hazelcast xsi:schemaLocation="http://www.hazelcast.com/schema/config hazelcast-config-3.0.xsd" xmlns="http://www.hazelcast.com/schema/config" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"> <instance-name>gcms_node_1</instance-name> ... </hazelcast>
For all other hazelcast specific settings, please consult the Hazelcast IMDG Documentation.
5 REST API
The ClusterResource of the REST API can be used to get information of the cluster and make a specific cluster node the current master.
Administration permission is required to access the ClusterResource.
6 Updating
The nodes of a CMS cluster can be updated individually. However, there are some important things to note:
- If an update contains changes in the database, those changes will be applied with the update of the first CMS cluster node. Since the database is shared between all CMS cluster nodes, the changes will be visible for all other (not yet updated) cluster nodes as well.
- Updates, that contain no database changes (or database changes, which are compatible with older versions) can be done while other cluster nodes are still productive.
- Updates, that contain incompatible database changes will be marked in the changelog. Additionally, when such an update is applied to the first cluster node, the cluster is specifically prepared for the update:
- The maintenance mode is automatically enabled (if this was not done before by the administrator).
- The current master node will drop its master flag, so no background jobs (scheduler tasks, publish process, dirting) will run anymore.
- Generally, it is strongly recommended that all nodes of a CMS cluster use the exact same version. This means that the intervals between updates of individual nodes should be as short as possible.